




Table of contents
In this tutorial we'll scrape entries from Oxford Dictionary of Economics and write them to a .csv.
EPUB Format
The EPUB format is an open standard for e-books created by the International Digital Publishing Forum. EPUB is designed for reflowable content, that can adapt its presentation to the reader device. The content documents are in XHTML (defined by a profile of HTML5) or SVG documents, etc., that describe the readable content of a Publication and reference associated media resources (e.g., images, audio and video clips).
Since XHTML (EXtensible HyperText Markup Language)is a structured markup language, paired with a XML/HTML parser like Beautiful Soup, it will help us extract the entries easily.
Prerequisites
All you need to build this project is a code editor of your choice and python 3 installed on your local machine. You can even use a browser based IDE like Replit to skip setting up an environment at all and jump right into writing code, which is what I did.
You can checkout my repl here.
Code
First we'll need to install our dependencies Beautiful Soup and EbookLib.
EbookLib
EbookLib will help us read EPUB files programmatically. Run the following command in your console to install EbookLib:
pip install EbookLib
Beautiful Soup
Beautiful Soup will help us scrape the resultant XML generated by EbookLib.
pip install beautifulsoup4
Along with this will also need to add our EPUB in the project directory so we can parse it. I have mine named oxford-dictionary-of-economics.epub which you can find in the project directory of the repl and the github repository.
Now let's discuss the code.
First we parse our oxford-dictionary-of-economics.epub file using epub.read_epub function provided by ebooklib library. This will allow us to read the contents of the epub.
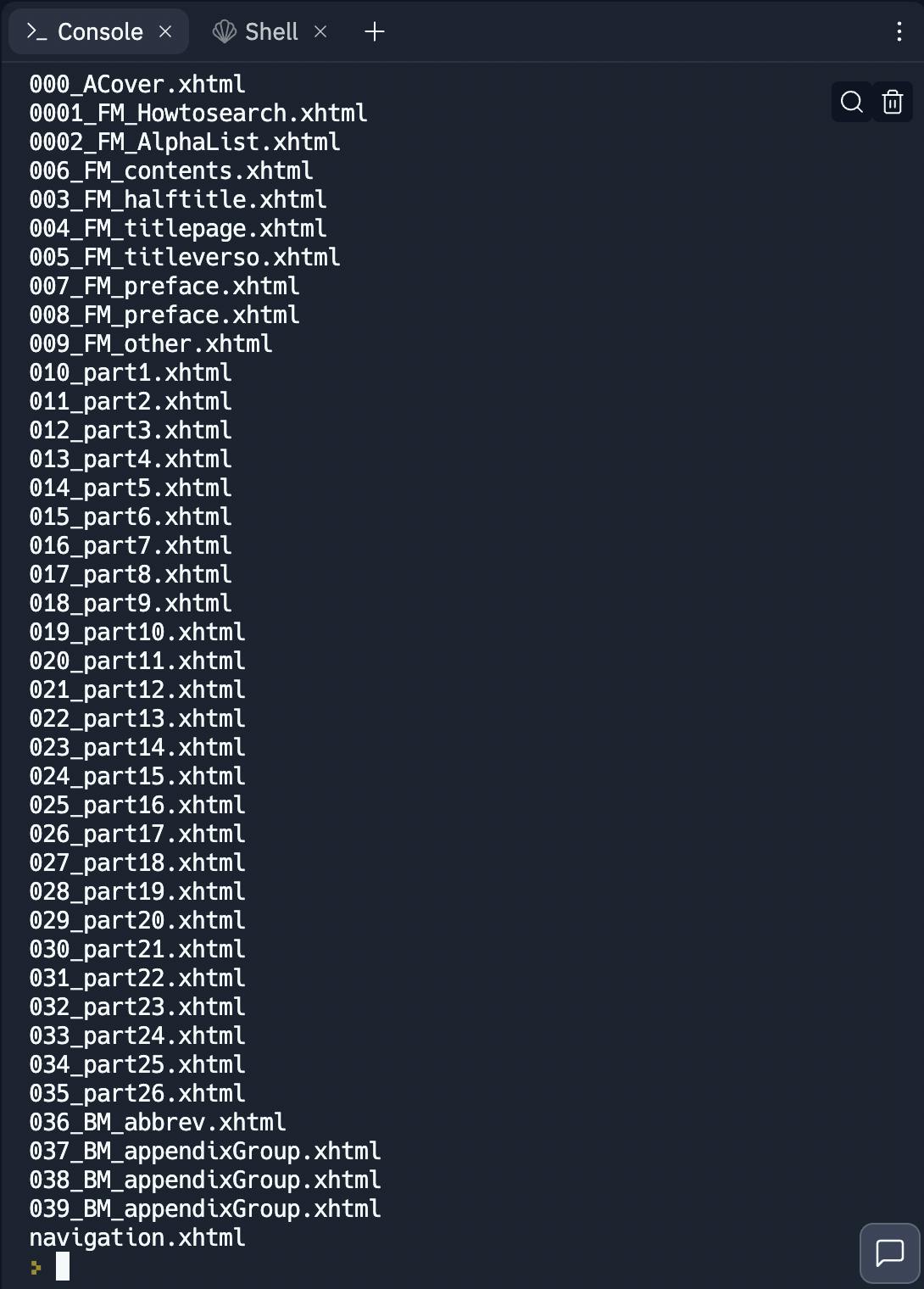
We want the text content of the EPUB so we want all items of type ebooklib.ITEM_DOCUMENT. This also contains content like the cover, title page, preface etc which we don't need. So we filter out the files containing _part in their name as they are the files that contain the entries. Here's the output of the commented out print(doc_name) line that helps us figure out which documents to store in our documents array.
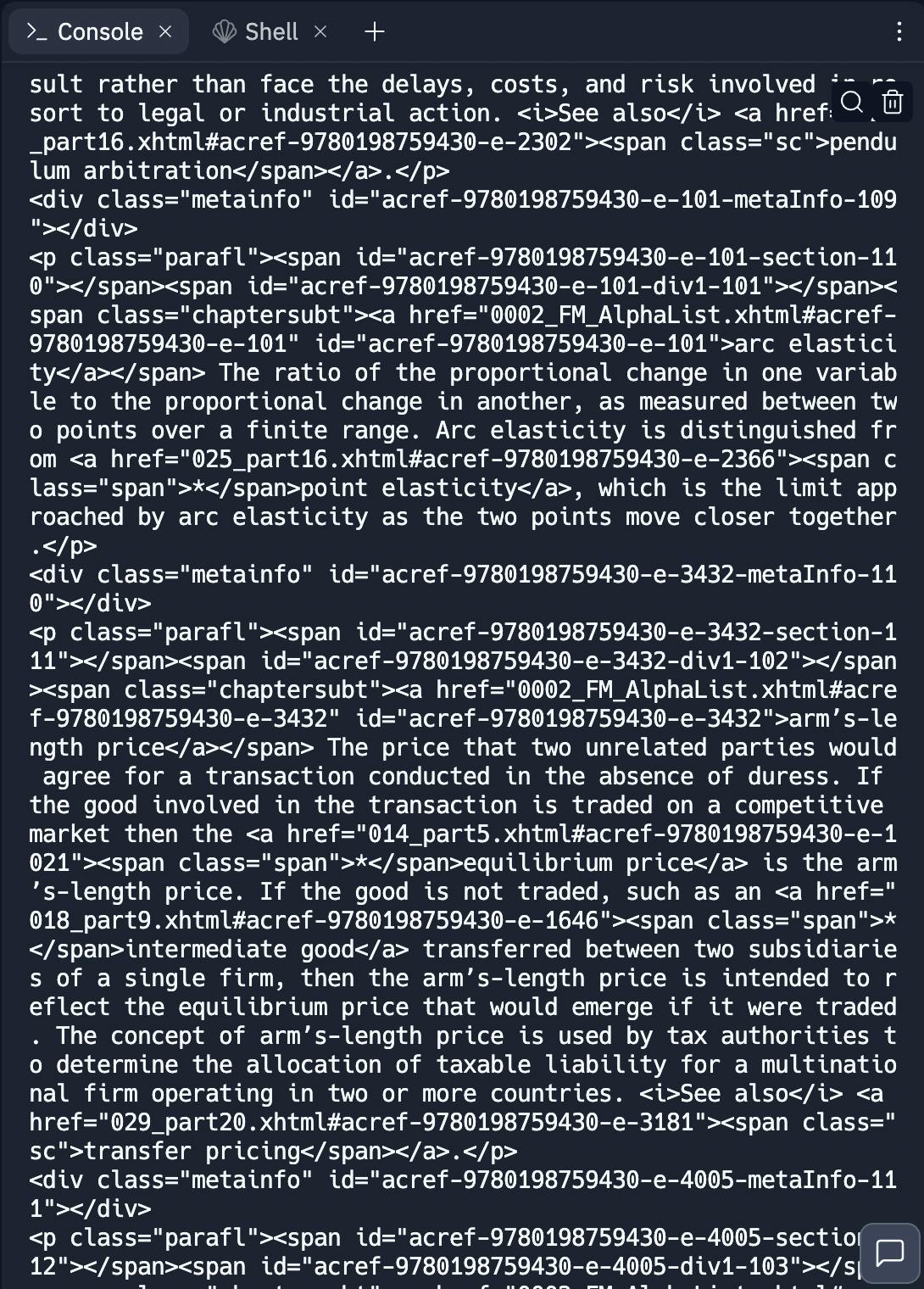
We'll first try to extract the data from a single document and then loop over all document to get all entries. To understand how the content is written in the xhtml file, we first print the output from parsing the body content from our first document in the documents array and using html.parser as our parser. The output looks like this:
We can paste this output in any html viewer to get a better understanding of the content. This is how the output looks when you preview the html.
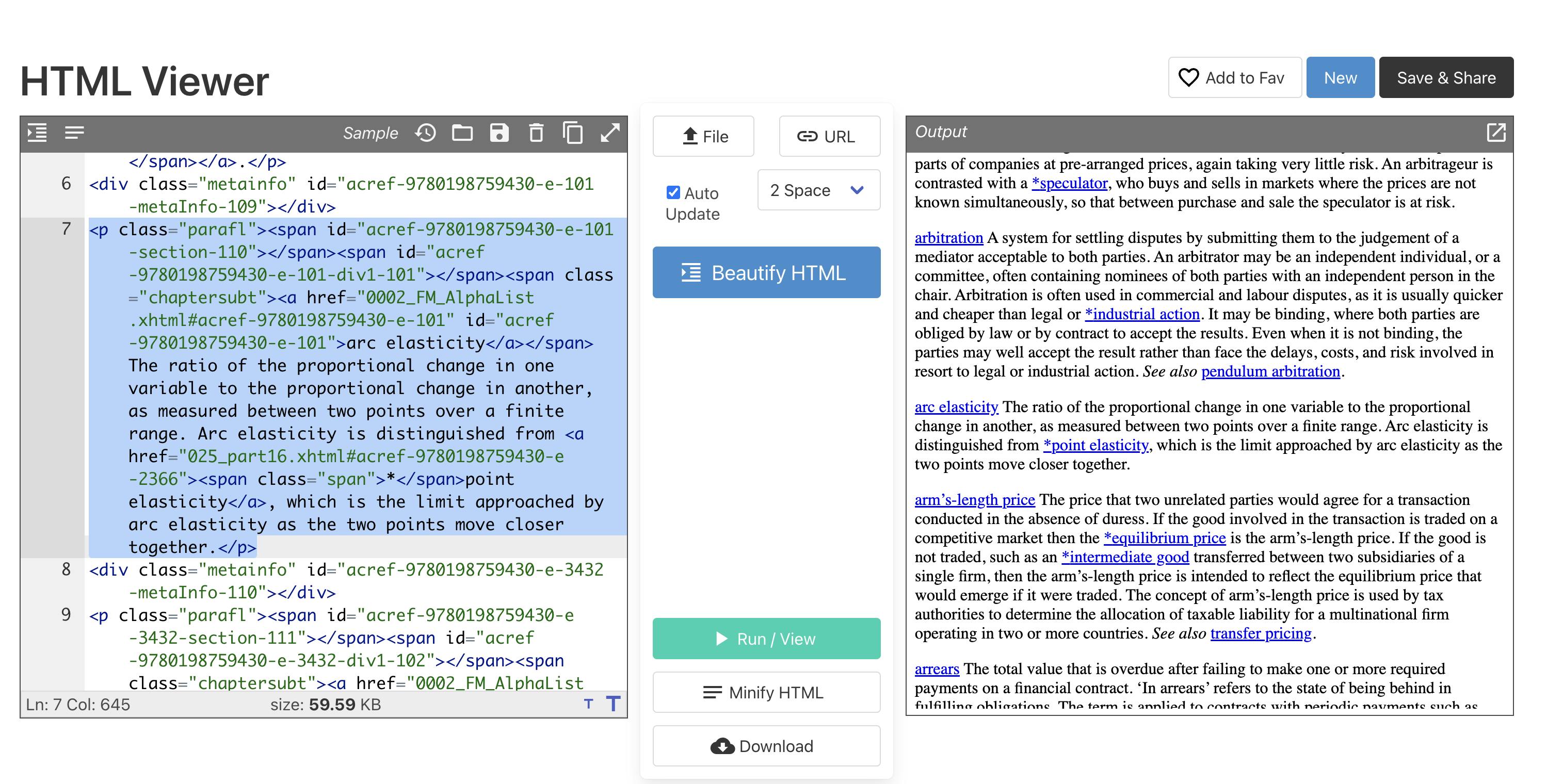 Notice that a single entry is in a block enclosed by
Notice that a single entry is in a block enclosed by <p> tags which contains the title enclosed in a <span> tag with the class name chaptersubt along with description which is the actual text within the <p> tags. So we extract a single paragraph from the parsed soup using para = soup.find("p") and then extract the title and description using title = para.find("span", {"class": "chaptersubt"}).get_text() and desc = para.get_text()[len(title)+1:] respectively. Notice that the description is a substring because para.get_text also returned the title in the description so we discard that part of the string. The extracted entry looks like this.
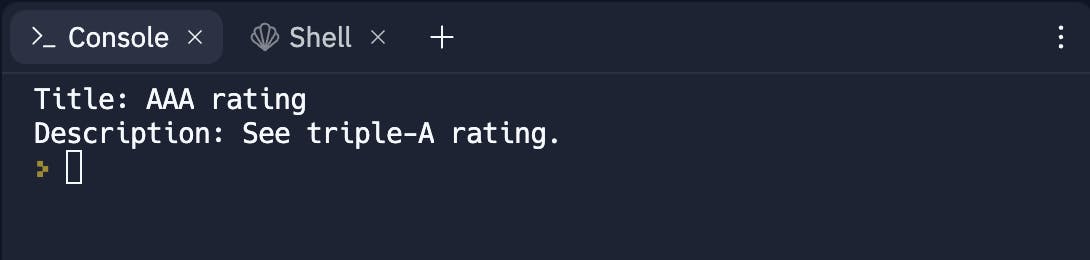
Now all that's left to do is repeat the same process for all the documents and store them in our entries array which is exactly what we do in the uncommented part of the code shown above.
We wrap our get_text calls in a try block because there are some span tags that don't contain text within them. We don't need to store them and we also don't want them to break the program, hence the try block.
Finally we write our entries into entries.csv file. I have also printed the number of entries extracted and the first 10 entries to see how they look. Here's a section of the output.

You can checkout all the entries in the entries.csv file from the repl or the github repo.
Project Links
You can checkout the project by either:
- running this repl on Replit. You can also look at the project files there.
- checking out the Github repo.
If you enjoyed this tutorial consider leaving a like and a follow 😉.